Dataset- and Task-Independent Recommender System
Dataset- and Task-Independent Recommender System (DTIRS)
Recommender systems offer personalized experiences but often require extensive dataset- and task-specific configurations, limiting reusability and accessibility. I To this end, we propose the Dataset- and Task-Independent Recommender System (DTIRS), which minimizes manual intervention by standardizing dataset descriptions and task definitions through the novel Dataset Description Language (DsDL). DTIRS enables autonomous feature engineering, model selection, and optimization, reducing the need for constant reconfiguration while still allowing model retraining.
For recommendation system tasks, we categorize them into four major types:
- Binary prediction
- Real-valued (numeric) prediction
- Ordered list prediction
- Unordered list (set) prediction
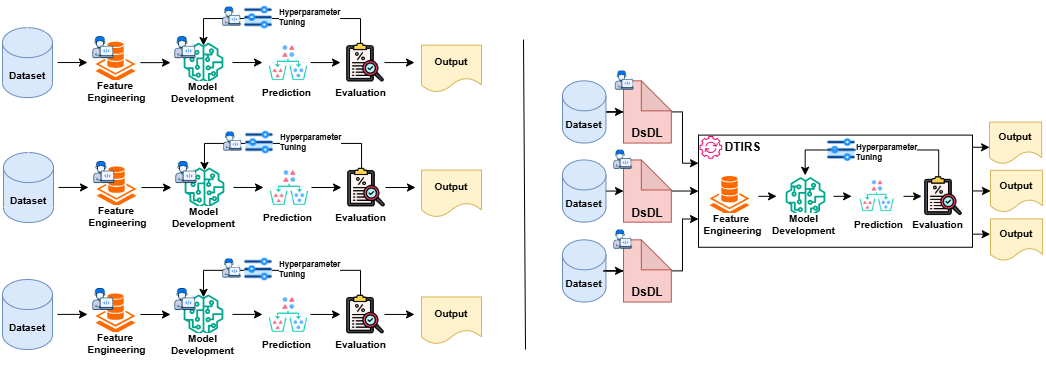
Overview of the typical recommender system workflow (left) compared to our proposed DTIRS (right). The typical workflow often requires human expert and manual effort for feature engineering, model development, and hyperparameter tuning across different datasets, creating a barrier to entry; the results are typically dataset- or task-specific codes or pipelines, reducing reusability. In contrast, with the help of DsDL (Section~\ref{sec:dsdl}), DTIRS aims to eliminate the need for manual reconfiguration in many of these steps, lowering the barrier to entry and increasing reusability.
1. DsDL Specification
DsDL (Dataset Description Language) is used to define the structure of datasets. The format is as follows:
DsDL ::= "columns" ":" "[" ColumnList "]"
[TimestampCol]
"target" ":" "[" TargetList "]"
ColumnList ::= Column { "," Column }
Column ::= "{" "col_name" ":" String ","
"type" ":" ColumnType "}"
ColumnType ::= "numeric" | "binary" |
"categorical" | "ordinal" |
"textual" | "url" |
"list_of_numeric" | "list_of_binary" |
"list_of_categorical" | "list_of_url" |
"list_of_ordinal" | "list_of_textual"
TimestampCol ::= "timestamp_col" ":" String
TargetList ::= "{" "type" ":" TargetType ","
"label_col" ":" String ","
"key_col" ":" String ","
[ "," "list_size" ":" PositiveInt
"," "relevance_col" ":" String ] "}"
TargetType ::= "binary" | "numeric" |
"ordered_list" | "unordered_list"
String ::= <any string>
PositiveInt ::= <any positive integer>
Descriptions:
columns: contains the set of the dataset columns with their column names and types.target: defines the prediction task, including the label or target variable (label_col), the key or identifier for that label (key_col), and additional parameters for list-based tasks (list_size,relevance_col). Without loss of generality, we require the type ofrelevance_colto be binary or numeric, where higher values means more relevant.timestamp_col(optional): specifies the time-related field name, if applicable.
2.Code Example
2.1 Project Structure
├── DCN/ # DCN example directory
│ ├── Criteo_tiny/ # Criteo tiny dataset
│ ├── dcn.py # Script od DCN model
| ├── main.py # Main script for running recommendation tasks of DCN algorithm
| ├── task.py # Abstract class defining the task interface
| ├── user_task.py # Implementation of DTIRS with DCN algorithm
|
├── real_dataset/ # Real-world dataset directory
│ ├── binary/ # Binary classification tasks
│ ├── numeric/ # Numeric prediction tasks
│ ├── ordered_list/ # Ordered list recommendation (Top-N)
│ ├── unordered_list/ # Unordered list recommendation (Tag Prediction)
│ ├── data_remove_label.py # Script to remove labels from dataset
│
├── synthetic_dataset/ # Toy dataset directory for testing
│ ├── binary/ # Binary classification toy dataset
│ ├── numeric/ # Numeric prediction toy dataset
│ ├── ordered_list/ # Ordered list toy dataset
│ ├── unordered_list/ # Unordered list toy dataset
│
├── main.py # Main script for running recommendation tasks
├── task.py # Abstract class defining the task interface
├── user_task.py # Implementation of different recommendation tasks
├── README.md # Project documentation
Gitlab Link: https://gitlab.com/dtirs/dtirs.gitlab.io
2.2 Code Dependency
Before running the code, make sure you have the following Python dependencies
Manually install them:
pip install pandas numpy pyyaml scikit-learn surprise
2.3 Running the Code
Execute main.py with the following parameters:
python main.py <train_data_path> <test_data_path> <dsdl_path> <output_path>
Parameter description:
<train_data_path>: Path to the training dataset (CSV file)<test_data_path>: Path to the test dataset (CSV file)<dsdl_path>: Path to the DsDL (Dataset Description Language) YAML file<output_path>: Path where the prediction results will be saved (directory)
Example usage:
python main.py data/train.csv data/test.csv config/dsdl.yaml output/
2.4 Code Description
main.py
- Loads the data, parses the DsDL file, and calls
UserTaskbased on the target task type. - Iterates through the targets defined in the DsDL file, performing preprocessing, model training, and predictions.
task.py
- Defines an abstract class
Task, which includes:preprocess_data(): Handles data processingtrain_model(): Trains the modelmake_predictions(): Generates predictions
user_task.py
- Implements
Task, providing:- Data Preprocessing: Handles different feature types (numerical, categorical, list-based)
- Model Training: Define model traning
- Predictions: Output the prediction base on different task types
2.5 Example using DCN algorithm
This section demonstrates how to use the Deep & Cross Network (DCN) model for binary classification tasks. The DCN model combines both deep learning and cross features to capture complex feature interactions.
a. Files Paths and Dataset
- File Path:
./DCN/– The task implementation file that defines how to process data, train the model, and make predictions. - Dataset: You can use your own dataset or the one provided in
./DCN/Criteo_tiny/depending on the type of task you want to perform. The dataset should includeDsDL.yamlfile
b. Task Description
The UserTask class in ./DCN/user_task.py defines the preprocessing, training, and prediction steps for the binary classification task. The DCN model is integrated during the training phase.
- Preprocessing: The categorical features like
user_idanditem_idare encoded usingLabelEncoder. The model is designed to handle both categorical and numeric features. Missing values are also processed during the preprocessing step. - Model Training: The
train_modelmethod creates an instance of the DCNModel class (defined in./DCN/dcn.py) for binary classification. The model is trained using the processed dataset, and the training is performed using the Adam optimizer and binary cross-entropy loss. - Predictions: After training the model, the
make_predictionsmethod is used to generate predictions on the test dataset. These predictions are saved to a CSV file at the specified output path.
3. Resource
Example Dataset: https://gitlab.com/dtirs/dtirs.gitlab.io/-/tree/main/synthetic_dataset
Example Code: https://gitlab.com/dtirs/dtirs.gitlab.io/-/blob/main/user_task.py